
티스토리 뷰
기록하게 된 이유
팀 서비스 중 OOM으로 장애를 겪은 회고를 적어본다.
장애가 실제 발생했을 때는 사실 GC나 jvm memory에 대한 경험이 부족해서
원인 분석을 위해 어디부터 확인해야 될지 몰랐고, 허겁지겁 찾느라 원인 후보들에 대한 이해가 완전하지 않았다.
하지만 다시 내용을 처음부터 살펴보니, 에러가 발생한 원인은 정말 생각지도 못한 부분이라 개인적으로 흥미로웠고,
공부할 만한 내용들이 많다고 생각들어서 늦게나마 회고 형태로 정리해본다.
장애 상황
서비스 중인 서버 10대 중 대부분에서 DB Connection 에러와 함께 java oom 이 발생했다.
1차 대응으로 전체 was를 재기동 해봤지만, 얼마 지나지 않아 서비스 중단은 계속됐다.

용의자 1. Slow Query
DB connection과 java oom 이 두 가지를 연결해보면 때 처음 떠오르는 원인은 Slow Query이다.
API 중 매우 느린 쿼리가 계속해서 DB connection을 잡아먹으면서 오랫동안 서버 리소스를 점유하고,
계속해서 새로 들어오는 Request 때문에 결국 oom 이 발생하면서 서비스가 중단된 것이 원인이라 생각했다.
Slow query를 유발하는 원인은 여러 가지가 될 수 있는데, 기본적으로는 이런 이슈들일 것이다.
- 인덱스가 제대로 걸려있지 않았거나
- 너무 큰 데이터셋에 대한 연산 (조인, 정렬, 조회 etc.)
- 하드웨어 이슈 (물리적으로 부족한 메모리, cpu etc.)
- 락을 유발하는 트랜잭션
실제로 장애발생 시간대에 확인해본 결과 full-scan을 하는 로직이 있어서 200만건이 넘어가는 fetch 문이 오랜 시간 동안 connection을 잡고 있는 것을 확인 할 수 있었다.
오래걸린 API 로그 트레이스를 확인해보니 잘못된 요청 형식으로 인해 쿼리 안에 들어갈 where 절 파라미터가 의도치 않게 null로 들어가게 되어 full scan을 유발하고 있었던 것이다. (관련 오류)
빠르게 내용을 확인하고, 장애 발생 후 약 2시간 만에 다음 수정 사항들로 배포를 했다.
- full scan 하지 않도록 쿼리 수정
- db connection pool size 수정
- maxLifetime 수정
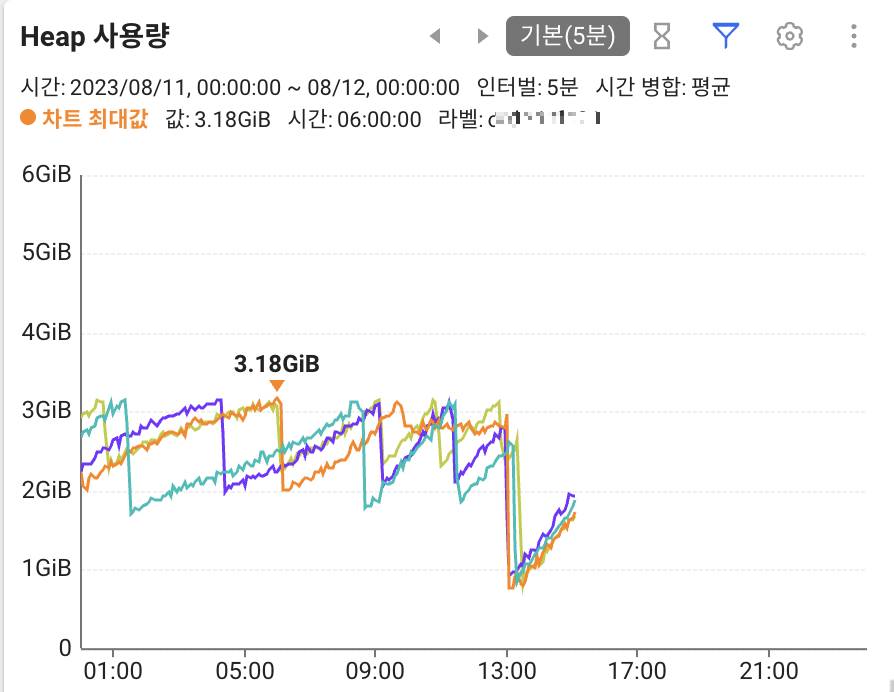
배포 이후 장애는 발생하지 않았지만, 이상하게도 계속해서 oom 나기 직전의 수준으로 아슬아슬하게 heap 메모리가 차는 현상이 계속 되었다.
용의자 2. disk usage 100%로 인한 log thread?
OOM이 발생한 서버들은 공통적으로 /log 의 disk use가 100% 였다.
용량이 이미 꽉 찬 상태로 logback에서 로그를 쓰려고 할 때 일종의 lock 같은 에러로 인해서 memory leak이 발생하는 것은 아닐까 하는 생각이 들어서 개발(stage)환경에서 이를 테스트 하기로 했다.
/log 의 disk usage를 100%로 만들고, 메모리를 많이 쓰는 api를 찾아서 ngrinder로 부하 테스트를 해보았다.
Starting rsync openapiserverapp WAS Contnets...
/app/was/tomcat/embedded/script/sync_inst.sh: line 26: /log/was/openapiserverapp/info.log: 장치에 남은 공간이 없음공간이 없다는 로그를 남기긴 하지만, WAS는 중단되지 않았다.
원인은 역시나 이게 아니었다.
용의자 3. Heap dump로 찾은 header 사이즈
서버의 JVM heap dump를 처음에 떠봤을 때는 정확한 이슈를 찾기 힘들었다.
그러나 tomcat을 들여다 보니 이상하게 보이는 부분이 있었다.
클라이언트로부터 받은 Request의 헤더 사이즈가 이상할 정도로 컸다. (무려 10MB)
헤더 사이즈는 클라이언트 별로 다르게 설정 할 수 있기에 이는 처음에는 클라이언트에서의 실수로 보일 수 있지만,
모든 request가 똑같이 10MB로 되어있다는 것은 확실히 우리 쪽에 이슈가 있다는 것이다.
Request 헤더에 대한 설정이 있나 확인해보니 application.yml에 헤더 사이즈 설정을 하고 있었는데...
무려 몇 달 전에 휴먼에러로 tomcat에서 설정하는 헤더 사이즈 설정이 10kb가 아닌 10mb로 할당하고 있던 것이다..!

Spring-boot는 내장 tomcat을 사용하기 때문에, web과 was가 같은 jvm을 공유한다.
tomcat에서 header에 대한 메모리 할당을 엄청 많이 하면서 oom이 발생했고, 이를 was에서 더 이상 메모리를 쓸 수 없게 된 것이다.
(max-http-header-size에 대한 자세한 정보)
해결 후 모니터링

해당 설정을 수정해 준 이후에 모니터링 결과, 배포 시점 이후로 free 되는 heap 공간이 더 많아졌다.
확실히 원인이 해결되었다!
마무리
현상을 해결하기까지 꽤 오랜 시간이 걸렸다는 점에서 이번 장애는 개인적으로 기억에 오래 남을거 같다.
처음 대처했던 방식이 실제 메모리를 잡아먹는 것을 어느 정도 해결해서 전 서버가 oom 나는 케이스는 막아줬기 때문에
서비스 전면 장애는 발생하지 않도록 하는 최소한의 차원에서 근본적인 원인을 계속 가진 채로 서비스 운영을 했던 것이다.
이렇게 생각하면 oom을 유발한 원인은 사실 여러가지였고 그 중에 가장 기여도가 컸던 원인이 헤더 사이즈 설정 에러라고 할 수 있다.
또한 발견하기 쉽지 않았고 만약에 대충 GG치고 서버 리소스를 늘리는데 그쳤다면 대충 돈으로 때우는 걸로 해결하고 넘어가지 않았을까?
나중에 원인을 찾고 나선 생각보다 너무나도 단순한 문제여서 놀랐다.
그리고 실제 해결하게 된 방법은 이론적으로만 알고 있던 jvm heap dump를 직접 들여다 볼 수 있는 좋은 경험이었던거 같다.
근데 또 이제 와서 생각해보니 max-http-header-size 라는 명칭은 좀 오해의 소지가 있어보인다.
max라고 하면 보통 최대 사이즈를 지칭하는거지 고정으로 할당하는 크기가 아니지 않나?
무튼 제대로 꽤 긴 기간동안 해결책이 안보이던 이슈라서 이번에 정리하면서 많은 것을 배우고 간접적으로 경험할 수 있게 되어 재밌었다.
'실무 개발 > 삽질 기록' 카테고리의 다른 글
| MSA 환경에서 로그 조회 시간 단축하기 (0) | 2024.07.22 |
|---|---|
| okhttp3 IOException: unexpected end of stream on Connection (0) | 2023.10.31 |
| JWT 토큰으로 Stateless한 인증하기 (0) | 2023.06.05 |
| java.util.regex.PatternSyntaxException: Dangling meta character (replace(), replaceAll()의 차이) (0) | 2022.01.21 |
- Total
- Today
- Yesterday
- KAKAO 2021
- Spring
- IOC
- 카카오 인턴
- nginx 내부
- PatternSyntaxException
- 프로그래밍 모델
- Java
- 디자인패턴
- okhttp3
- 카카오코테
- 2021
- 스프링
- 모던 자바 인 액션
- 2019 Kakao Blind
- jvm
- zipkin
- spring cloud sleuth
- behavior parameterization
- Kakao Blind
- 카카오
- 카카오 코테
- WORA
- 2020 KAKAO
- Java #JIT #JVM
- Java #GC #가비지콜렉터 #Garbage Collector
- decorator
- WORE
- 신규 아이디 추천
- 코테
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |